TL;DR
Shipped basic RAG and hit the wall? Agentic RAG is the upgrade path. Five patterns explained, framework verdict, eval pipeline, cost reality, and when NOT to go agentic. Production-tested.

By Vishvajit Pathak, Co-Founder, MarsDevs • Published April 30, 2026
Agentic RAG costs 3-10x more tokens and adds 2-5x latency versus one-pass RAG. It earns that price on multi-hop questions, ambiguous queries, and high-stakes domains (legal, medical, financial). It does not earn it on FAQ bots or single-fact lookups. We have shipped production RAG systems at MarsDevs across healthcare, fintech, and SaaS. The 2026 default stack: LangGraph for orchestration, LlamaIndex Workflows for retrieval, Ragas + Phoenix + Langfuse for evaluation. Production targets: faithfulness ≥0.9, answer relevancy ≥0.85, context precision ≥0.8. Build cost: $8K-$50K at MarsDevs, 3-16 weeks.
Four shifts moved RAG from clever demo to production discipline. The Model Context Protocol (MCP) became the standard retrieval-tool surface after Anthropic donated it to the Linux Foundation's Agentic AI Foundation in December 2025, and OpenAI plus Google adopted it. Provider-side retrieval went first-class: Anthropic's Citations API ships guaranteed pointers where cited_text does not count against output tokens, and OpenAI's File Search Tool in the Responses API provides managed retrieval over uploaded files. Reranker quality jumped. Voyage AI rerank-2.5{:target="_blank"} now outperforms Cohere Rerank v3.5 by 10-12% on instruction-following benchmarks. Evaluation matured from "does this answer look right" to standardized faithfulness and context-precision metrics through Ragas, Arize Phoenix, and Langfuse.
If you have shipped basic RAG and hit the wall, this is your upgrade path. If you have not shipped a basic RAG yet, start with our RAG fundamentals guide and come back here once you have a working v1.
| What changed | 2024 reality | 2026 reality |
|---|---|---|
| Tool protocol | Custom tool wrappers per framework | MCP (Linux Foundation, donated Dec 2025) |
| Provider retrieval | None | Anthropic Citations API, OpenAI File Search Tool, Gemini Grounding |
| Reranker leader | Cohere Rerank v3 | Voyage AI rerank-2.5 (10-12% lift over Cohere v3.5) |
| Eval surface | LLM-judge only | Ragas + Phoenix + Langfuse, with golden-set discipline |
| Default orchestration | LangChain chains | LangGraph stateful graphs |
| Multi-hop | Manual chain-of-thought | Self-RAG, CRAG, Adaptive RAG patterns |
The implication is concrete. A 2024 RAG project that took two engineers six weeks now takes one engineer four weeks at the same quality. The upgraded version (agentic, evaluated, observable) takes the same six weeks and costs 3-10x more in tokens at runtime. The build is faster. The runtime is heavier. Both are true.
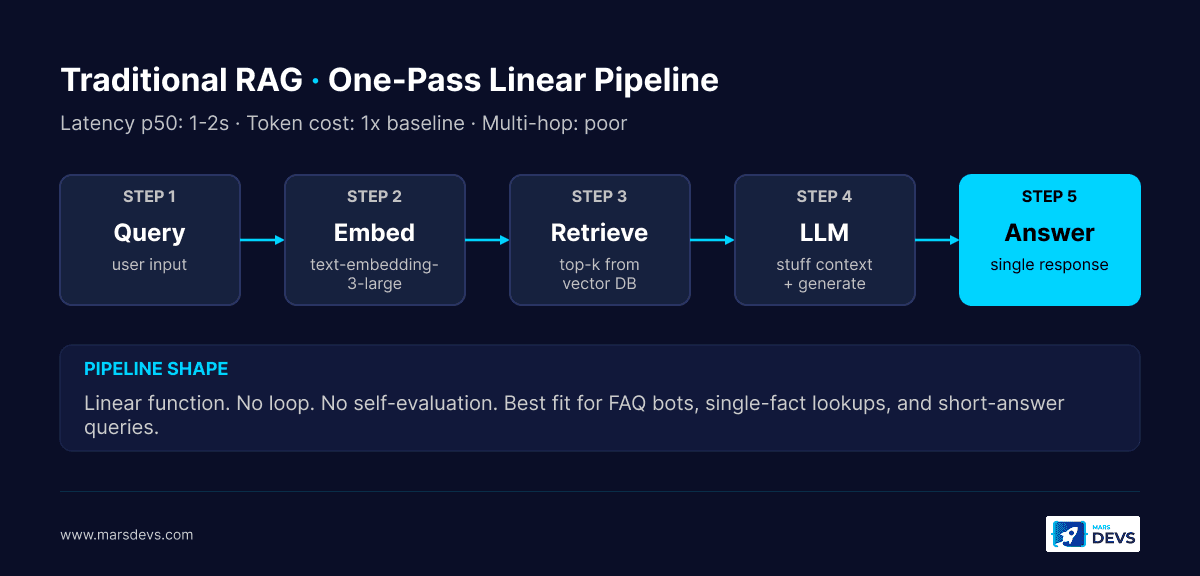
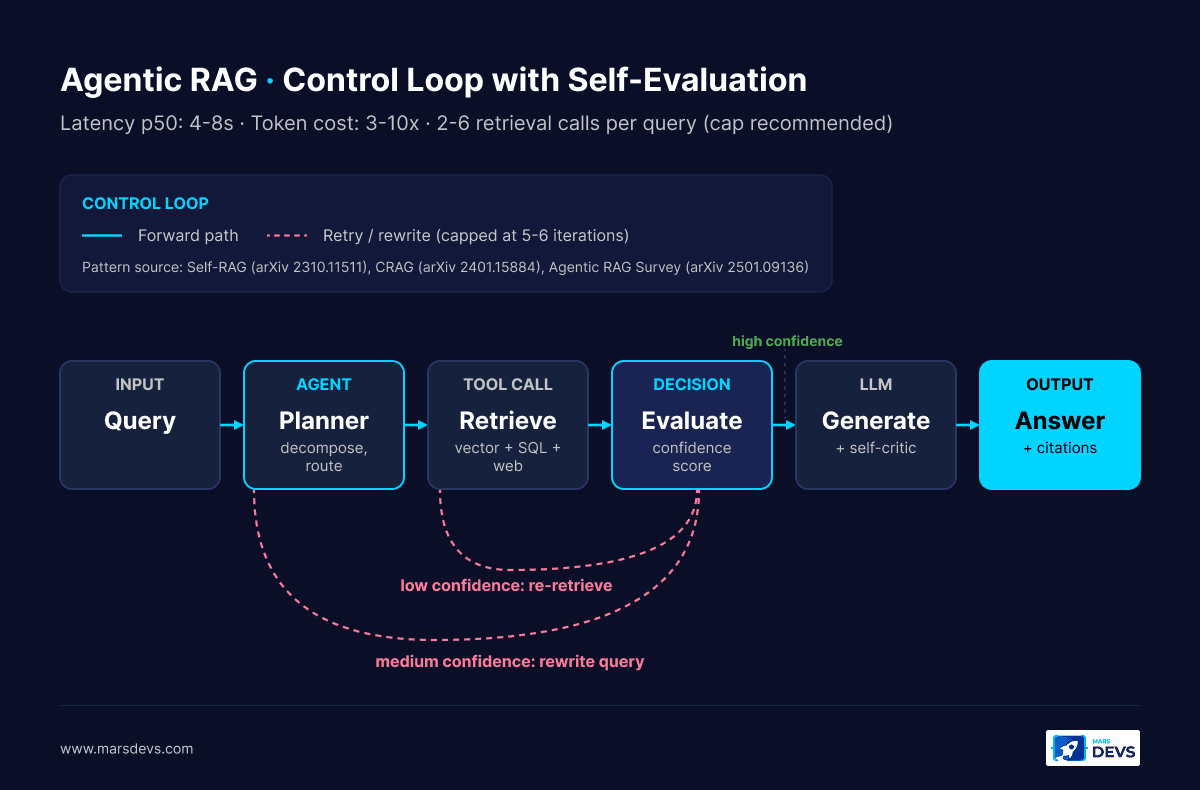
Traditional RAG is one-pass. You embed the query, retrieve top-k from a vector index, stuff the chunks into a prompt, and generate. Agentic RAG wraps that pass in a control loop. An LLM agent plans, decomposes the query, retrieves iteratively, evaluates what came back, decides whether to keep going, and self-critiques the final answer. The agent can call multiple tools (vector DB, SQL, web search, MCP server), reformulate queries when retrieval fails, and stop when confidence clears a threshold.
The shift is from a pipeline to a state machine. Traditional RAG is a function. Agentic RAG is a controller.
| Dimension | Traditional RAG | Agentic RAG |
|---|---|---|
| Control flow | One-pass linear pipeline | Graph or loop with state |
| Retrieval calls per query | 1 | 2-6 (iteration cap recommended) |
| Latency p50 | 1-2 seconds | 4-8 seconds |
| Latency p95 | 2-4 seconds | 10-15 seconds |
| Token cost vs vanilla | 1x | 3-10x |
| Multi-hop support | Poor | Strong |
| Tool use | None or fixed | Dynamic per step |
| Evaluation surface | Output only | Per-iteration trace |
| Best for | FAQ, lookups, short-answer | Multi-hop, ambiguous, regulated |
| Worst for | Multi-hop reasoning | Sub-3-second UX |
| MarsDevs build cost | $8K-$25K | $25K-$50K |
| MarsDevs build timeline | 3-8 weeks | 8-16 weeks |
The choice is not "which is better." The choice is "which earns its budget on this query class." A customer-service bot that answers "what is your refund policy" should never reach the agent loop. A diligence assistant that answers "compare clause 4.2 across our last five vendor contracts and flag any that conflict with the new SOC 2 framework" cannot work without one.
Building agentic RAG? We have deployed it in production across multiple verticals. Book a free strategy call.
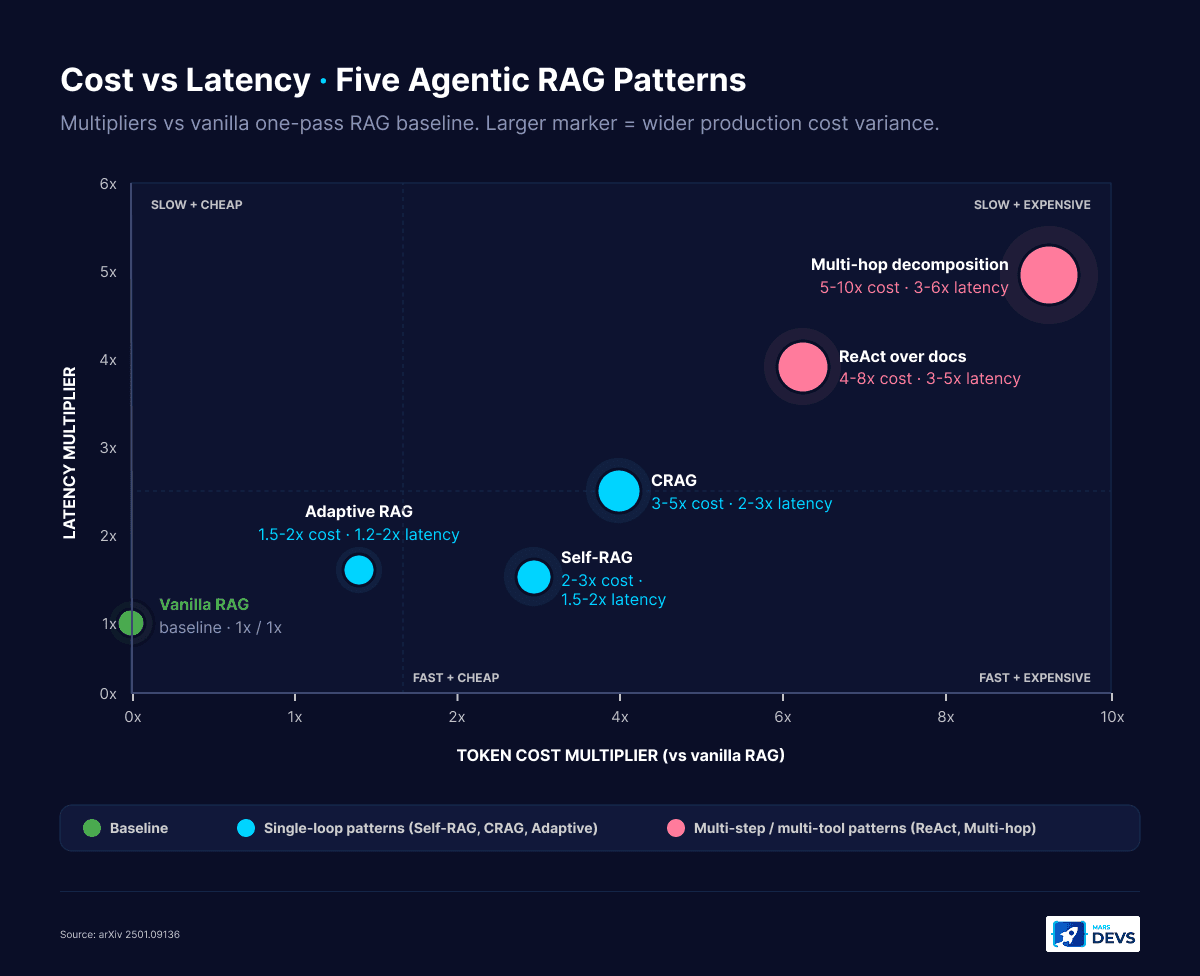
Production agentic RAG in 2026 is built from five named patterns. Self-RAG (model emits reflection tokens), Corrective RAG or CRAG (retrieval evaluator with corrective routing), Adaptive RAG (classifier picks pipeline depth), ReAct over documents (reason-act loop on retrieval tools), and multi-hop query decomposition (break and recompose). Most production systems combine two or three. Pure single-pattern deployments are rare and usually wrong.
The canonical taxonomy lives in the Agentic RAG survey paper{:target="_blank"} (arXiv 2501.09136). Read it once. Then pick patterns based on your query distribution, not the paper's elegance.
| Pattern | Best for | Latency multiplier | Token multiplier | Implementation effort |
|---|---|---|---|---|
| Self-RAG | Single-pass retrieval with self-grading | 1.5x-2x | 2x-3x | Medium (needs reflection tokens) |
| CRAG | Variable-quality knowledge bases | 2x-3x | 3x-5x | Medium |
| Adaptive RAG | Mixed-difficulty query streams | 1.2x-2x average | 1.5x-2x average | Low (classifier upfront) |
| ReAct over docs | Hybrid doc + structured + web | 3x-5x | 4x-8x | High |
| Multi-hop decomposition | Comparison, analytical questions | 3x-6x | 5x-10x | High |
Self-RAG trains the model to emit special reflection tokens (Retrieve, IsRel, IsSup, IsUse) that decide when to retrieve, whether retrieved passages are relevant, whether the generation is supported by them, and whether the answer is useful. The model self-grades each step. Asai and colleagues introduced this in 2023, and the LangChain self-reflective RAG with LangGraph guide{:target="_blank"} shows how to wire it into a graph runtime.
When it wins: queries where the retrieval signal is noisy and the model needs to reject bad chunks. Customer support over a fast-changing knowledge base is the obvious fit.
When it loses: queries where retrieval is reliably good. The reflection-token overhead becomes pure waste. Single-fact lookups also lose because the self-grade adds a round-trip for no gain.
Framework support: LangGraph (best, native checkpointing on each reflection step), LlamaIndex Workflows (workable, less natural), CrewAI (forced fit).
CRAG inserts a lightweight retrieval evaluator between retrieval and generation. The evaluator scores retrieved documents on confidence and routes to one of three actions. High confidence: use the documents as-is. Low confidence: discard them and trigger a web-search fallback. Mid confidence: keep the documents and supplement with web search. The original CRAG paper{:target="_blank"} (arXiv 2401.15884) by Yan and colleagues is still the cleanest source.
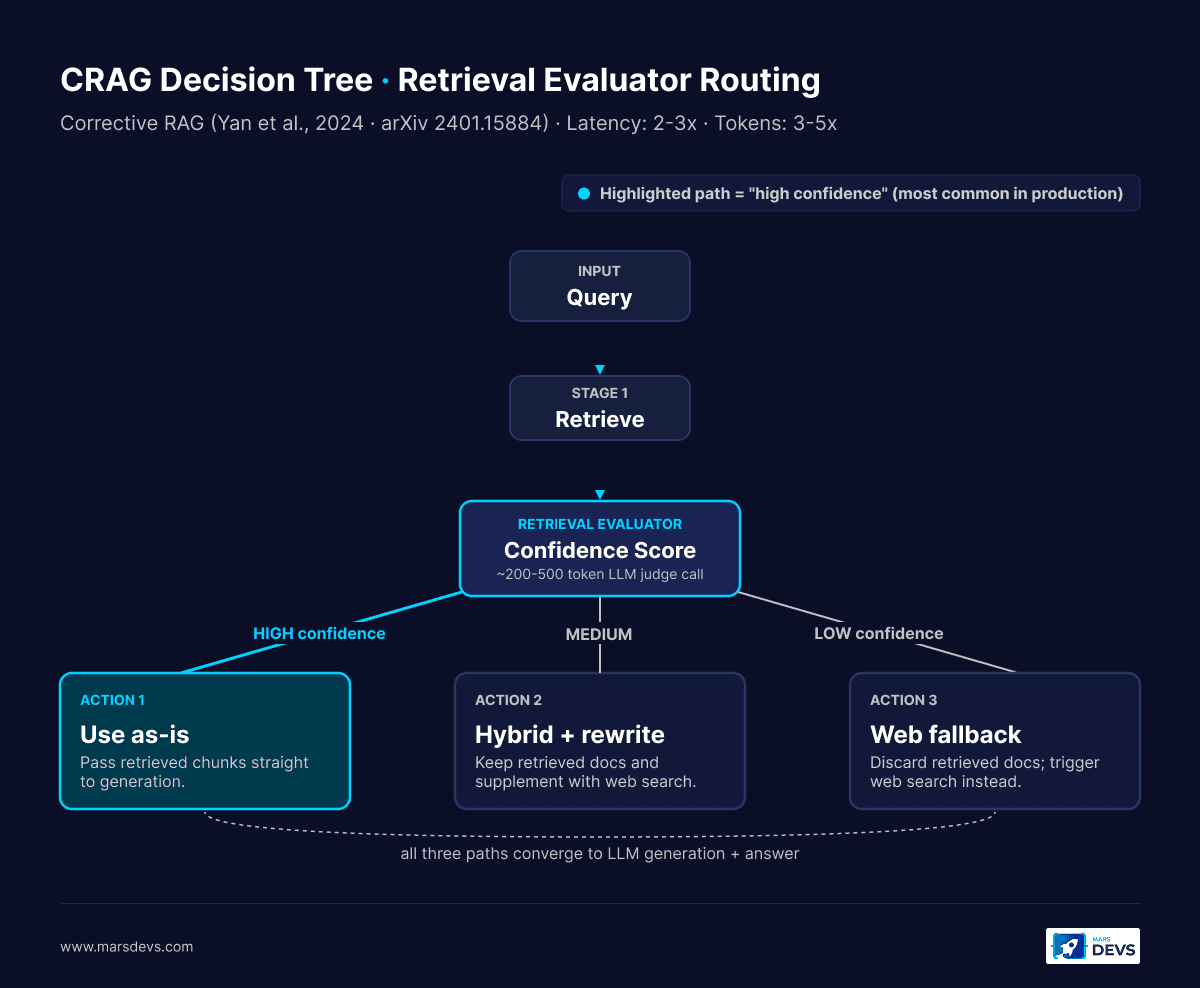
When it wins: knowledge bases with uneven quality. Half your corpus is high-confidence (product docs), half is messy (forum threads, support tickets). CRAG quietly upgrades the messy half by triggering web fallback when needed.
When it loses: closed-domain settings where web fallback is forbidden (legal, regulated finance, healthcare with PHI). You can swap the web step for a secondary retriever, but the routing logic still runs and adds cost.
Framework support: LangGraph (graph-native), LlamaIndex Workflows (event-driven fits CRAG's branching), CrewAI (clumsy), AutoGen (fine).
Adaptive RAG puts a small T5-large classifier in front of the retriever to predict query difficulty: no retrieval needed, single-step retrieval, or multi-step retrieval. Easy queries skip the agent entirely. Hard queries enter the loop. The classifier costs ~5-15 milliseconds per query, which is cheaper than the 3-8 seconds you save on the easy path.
When it wins: query streams with mixed difficulty. A typical product chatbot has 60-80% lookup queries and 20-40% reasoning queries. Adaptive routing cuts average cost by 30-50%.
When it loses: query streams that are uniformly hard. If every query needs multi-hop reasoning, the classifier is a tax for no benefit.
Framework support: any framework, since the classifier sits at the edge. We default to LangGraph for the routing graph and LlamaIndex Workflows when retrieval depth is the dominant work.
The ReAct pattern (reason-act loop) generalizes to retrieval when the agent can call multiple tools per step. The agent reasons about what to fetch, calls a retrieval tool (vector DB, SQL, web, or an MCP server), reads the result, reasons about the next step, and stops when it has enough. The pattern shines when you have heterogeneous sources, like a vector store plus a Postgres analytics table plus a web fallback.
When it wins: hybrid sources. A diligence agent that needs unstructured docs plus financial data plus current news cannot work in any other shape.
When it loses: pure unstructured RAG. The tool-selection overhead is wasted when there is only one tool.
Framework support: LangGraph (best for state), AutoGen (good for conversational ReAct), CrewAI (role-based ReAct), Haystack (production-shaped, less flexible).
Multi-hop decomposition takes a complex query, asks the LLM to break it into independent sub-questions, retrieves for each in parallel, and recomposes the answer. "Compare X and Y across dimensions A, B, C" becomes six retrieval calls instead of one. Latency stays manageable because the sub-retrievals run in parallel. Cost goes up linearly with the fan-out.
When it wins: comparison queries, aggregations, "summarize across N documents."
When it loses: queries that are not actually decomposable. The LLM will happily invent sub-questions for a single-fact lookup, which blows cost for nothing.
Framework support: LlamaIndex Workflows is the strongest here because its retrieval modules are mature and its async-first runtime parallelizes naturally. LangGraph also works.
The 2026 production retriever is two-stage with an optional third. Stage one: hybrid search combining BM25 (sparse) and dense embeddings, returning the top 50 candidates. Stage two: cross-encoder rerank (Voyage AI rerank-2.5 or Cohere Rerank v3.5) returning the top five for the LLM. Stage three (optional): a GraphRAG layer for relationship and cross-document queries. Two-stage hybrid plus rerank achieves Recall@5 around 0.816 versus 0.695 for hybrid alone in published benchmarks. That is a 17% jump that translates directly into faithfulness gains downstream.
Chunking: semantic chunking outperforms fixed-size in every test we have run. Aim for 512-1024 tokens with 50-100 token overlap. Chunk by section header where the document structure allows.
Embeddings: text-embedding-3-large for general-purpose, voyage-3 when domain accuracy matters, sentence-transformers for cost-sensitive prototypes. The 2026 default we ship is text-embedding-3-large for breadth and voyage-3 for any retrieval-heavy production workload.
Vector DBs: Pinecone is the managed default. Qdrant is the agent-memory leader (Rust-based, fast filtering). pgvector inside Postgres is what we use for early-stage MVPs because it removes a service from the stack. Weaviate is strong if you want native GraphQL and hybrid out of the box. Chroma is for prototypes only.
Rerankers: Voyage AI rerank-2.5{:target="_blank"} is the 2026 leader, with rerank-2.5-lite as a cheaper option for cost-sensitive workloads. Cohere Rerank v3.5 is still solid and has the broadest framework integrations. Jina AI reranker is a credible open option.
For a fuller stack discussion, see our take on the 2026 startup tech stack.
LangGraph is the MarsDevs default for stateful agentic RAG in 2026. LlamaIndex Workflows is the default for retrieval-heavy single-pipeline agentic. CrewAI fits role-based prototypes. AutoGen wins inside Azure environments. Custom orchestration is for teams with very specific performance budgets where 14ms of overhead matters.
The verdict is not framework loyalty. It is fit. LangGraph models control flow as a directed graph with explicit state, native checkpointing, and human-in-the-loop pauses. That is exactly what stateful multi-agent RAG needs. LlamaIndex Workflows is event-driven, async-first, and ships with the deepest retrieval module library. That is exactly what a retrieval-heavy single-pipeline agent needs.
| Framework | Orchestration model | RAG depth | State persistence | Overhead per call | Tracing | MarsDevs verdict |
|---|---|---|---|---|---|---|
| LangGraph | Directed state graph | Medium (via LangChain) | Native checkpointing | ~14ms / 2.4K tokens | LangSmith | Default for stateful multi-agent control |
| LlamaIndex Workflows | Event-driven async | Deep (mature retrieval) | Workflow context | ~6ms / 1.6K tokens | LlamaTrace, Phoenix | Default for retrieval-heavy single-pipeline |
| CrewAI | Role-based crews | Shallow | Manual | Higher (orchestration tax) | Limited | Prototype only |
| AutoGen | Conversational multi-agent | Shallow | Manual | Medium | Azure-native | Pick if you live in Azure |
| Custom | Whatever you build | Whatever you build | Whatever you build | Lowest | Roll your own | Only with specific perf needs |
The strongest 2026 stacks combine two frameworks. LlamaIndex handles retrieval, indexing, and chunking. LangGraph handles the agent control flow on top. The boundary is clean: LlamaIndex hands documents to the LangGraph agent through a tool interface. We ship this combination on most production builds.
For deeper comparisons, see LangChain vs LlamaIndex and LangGraph vs CrewAI vs AutoGen.
Three production-grade managed retrieval surfaces shipped in late 2025 and early 2026. The Anthropic Citations API{:target="_blank"} provides guaranteed pointers from generation back to source documents, and cited_text does not count against output tokens. OpenAI's File Search Tool inside the Responses API offers managed retrieval over uploaded files with no vector DB to operate. MCP retrieval servers give you a standardized tool interface across providers, with official servers for Google Drive, Slack, GitHub, Postgres, Puppeteer, filesystem, Brave Search, and Fetch.
The trade is real. Managed retrieval ships in days, not weeks. You give up cost control and domain-specific retrieval logic in exchange. Custom retrieval costs more upfront but gives you the dial on chunking, hybrid weighting, and reranker choice. We pick managed when speed-to-prod matters and the corpus is generic. We pick custom when retrieval quality is the product.
| Provider feature | Retrieval depth | Citation guarantee | Cost shape | When to use |
|---|---|---|---|---|
| Anthropic Citations API | Medium | Guaranteed pointer | Cited text excluded from output cost | Compliance and high-stakes citation surfaces |
| OpenAI File Search Tool | Medium | Yes, with retrieval scores | Per-MB stored + per-call retrieval | Speed-to-prod, generic corpus |
| MCP retrieval servers | Variable per server | Depends on server | Per-call to underlying source | Heterogeneous tool surface |
| Custom (LlamaIndex + Pinecone) | Deep | Yours to engineer | Compute + storage + reranker | Retrieval is the product |
MCP went from Anthropic's protocol to the de facto standard when it was donated to the Linux Foundation's Agentic AI Foundation in December 2025 and adopted by both OpenAI and Google. If you are building an agent in 2026 that touches external tools, MCP is the answer. There is no second-place choice anymore.
Production agentic RAG needs three eval layers. Per-query metrics through Ragas{:target="_blank"} give you faithfulness ≥0.9, answer relevancy ≥0.85, and context precision ≥0.8 as the production targets. Trajectory tracing through Arize Phoenix or Langfuse exposes every step of the agent loop so you can debug what the planner did wrong. Drift monitoring tracks knowledge-base, embedding, and eval drift weekly against a frozen golden set.
Skip any one layer and you will ship a system that looks fine in dev and degrades silently in production. The trio is the minimum.
| Metric | Ragas definition | Production target | What it catches |
|---|---|---|---|
| Faithfulness | Are claims supported by retrieved context | ≥0.9 | Hallucination |
| Answer relevancy | Does the answer match the question | ≥0.85 | Off-topic generation |
| Context precision | Are the right chunks retrieved | ≥0.8 | Bad retrieval |
| Context recall | Did retrieval miss anything | ≥0.85 | Missing chunks |
The evaluator paradox is real. Asking the same LLM that may hallucinate to grade retrieval quality is a circular dependency. Mitigations: ensemble eval with two model providers, freeze the golden set so trends are comparable, run human spot-checks on a sampled 5% of traces. Trust the trend more than any single number.
For deeper architecture context, see enterprise RAG architecture patterns.
Agentic RAG triples to quintuples latency. A standard RAG query takes 1-2 seconds. An agentic loop with three to four iterations takes 8-12 seconds. If your UX has a sub-3-second budget (chat, search-as-you-type, voice), you cannot run a full agent loop on every query. Use Adaptive RAG to route easy queries to single-pass and only ambiguous queries to the agent.
This is the most common mistake we see in production audits. Teams pick agentic RAG because the demo was impressive, ship it on every query, and watch p95 latency hit 18 seconds. Users abandon. The fix is upstream classification, not downstream optimization.
| Latency budget | Recommended pattern |
|---|---|
| Sub-1s | Vanilla RAG only. No agent loop. |
| 1-3s | Adaptive RAG: route 80% to vanilla, 20% to single-shot CRAG. |
| 3-8s | Self-RAG or single-iteration CRAG. Cap at 1 retry. |
| 8-15s | Full agentic loop with 3-4 iterations. CRAG, ReAct, multi-hop allowed. |
| 15s+ | Multi-hop decomposition with deep reranking. Use sparingly. |
Intelligent intent classification at the edge can cut costs around 40% and latency around 35% on typical mixed-traffic systems. That is the lever. Pull it before you optimize prompts.
Agentic RAG costs 3-10x more tokens than vanilla RAG at the same query volume. A system at 10,000 queries per day that runs $500 per day on vanilla RAG runs $1,500-$5,000 per day on agentic RAG before optimization. Caching, semantic cache, iteration caps, and Adaptive routing are the cost levers. Use all four.
| Query volume | Vanilla RAG (daily) | Agentic RAG (daily, before optimization) | Agentic RAG (after Adaptive routing + cache) |
|---|---|---|---|
| 100 / day | ~$5 | $25-$50 | $10-$20 |
| 1,000 / day | ~$50 | $250-$500 | $100-$200 |
| 10,000 / day | ~$500 | $1,500-$5,000 | $700-$2,000 |
| 100,000 / day | ~$5,000 | $15,000-$50,000 | $7,000-$20,000 |
Numbers indicative. Based on GPT-4o-class generation, text-embedding-3-large, and a Cohere or Voyage rerank stack. Actual costs depend on context size, model choice, and how aggressively you cache.
The build cost is separate from the runtime cost. Based on our AI development pricing, a production RAG system at MarsDevs costs $8,000-$50,000 to build in 3-16 weeks. Agentic complexity sits in the upper half of that band: $25,000-$50,000 over 8-16 weeks when self-correction loops, evaluation pipelines, and observability are scoped in. A bolt-on (query classifier plus retrieval evaluator on top of an existing pipeline) is closer to $8,000-$20,000 in 4-8 weeks.
If you are choosing between this and fine-tuning for the same problem, start with RAG vs fine-tuning. The short answer: RAG first, fine-tune only when the data is stable and the model needs a vocabulary it cannot learn from context.
Six failure modes repeat across every production agentic RAG system we have shipped. None of them appear in tutorials. All of them appear in week three of production traffic. The fixes below are what we run by default now.
Gotcha 1: Infinite iteration loops. An agent that can decide to retry will sometimes decide to retry forever. We cap iteration at 5-6 by default and escalate to a human or a graceful "I don't know" response on hitting the cap. Log every iteration. The pattern that triggers loops is almost always a knowledge-base gap that needs a human to add a source, not a smarter agent.
Gotcha 2: Knowledge base drift. Embeddings, chunking, and corpus content all silently degrade recall over time. A new document type lands, the chunker splits it badly, and Recall@5 drops 8% without anyone noticing. Track Recall@5 weekly on the frozen golden set. Alert on any drop greater than 3%.
Gotcha 3: Eval drift. Your golden set ages out. Real production failures shift faster than the set you froze nine months ago. Keep the frozen set for trend tracking. Maintain a separate fresh set you refresh monthly for the failure modes you are seeing now.
Gotcha 4: Cost tail. P95 cost is much worse than p50 cost. The mean tells a comforting lie. A few queries that hit the iteration cap and burn 30K tokens each can blow your daily budget by 4x while the mean stays flat. Set per-query token caps. Monitor the tail. Alert on p99 cost.
Gotcha 5: The evaluator paradox. LLM-judge metrics correlate with reality, but they are not reality. Ensemble two model providers as judges. Spot-check 5% of traces with a human reviewer. Trust the trend more than any single number.
Gotcha 6: Tool-call cascades. Agents that can call tools that call tools fan out exponentially. We had one agent that called an MCP server that called a sub-agent that called another retrieval tool and came back five seconds later with 47 nested traces. Bound the call graph depth at the orchestration layer. Alert on tree depth greater than 3.
We have deployed RAG systems for clients across healthcare, fintech, and SaaS. The pattern that kept cost predictable every time was Adaptive RAG routing: simple queries skip the agent entirely, and only the queries that need it pay the loop cost. For build-archetype context across our recent work, see the real cost of our last 5 SaaS builds.
Instrument everything with OpenTelemetry from day one. Phoenix and Langfuse both speak OTel natively. The traces you do not collect on day one are the failures you cannot debug on day 90.
We can help you avoid 6-12 months of mistakes. See how we have shipped agentic RAG before.
Yes, in three increments. Each step is independently shippable. Each step earns its budget on its own merit. You do not need to rebuild your existing RAG to ship agentic capabilities.
This is the path we use on every retrofit engagement. It maps cleanly to a 4-8 week project, with each step taking 1-3 weeks depending on existing observability.
Step 1: Add a query classifier in front of your existing retriever. A small model (T5-large or a fine-tuned distil-BERT) predicts query difficulty. Easy queries pass through to your current pipeline unchanged. Complex queries enter the agent loop. Time: 1-2 weeks. Cost lift: low. Latency lift on easy queries: zero. Cost saved on agent runs: 30-50%.
Step 2: Add a CRAG-style retrieval evaluator after retrieval. Score retrieved chunks for confidence. If confidence is below threshold, trigger query reformulation or a web fallback. The evaluator is a single LLM call costing roughly 200-500 tokens. Time: 1-2 weeks. Faithfulness lift: 5-15% on noisy corpora.
Step 3: Add reflection or self-critique on the generation step. After the LLM generates an answer, a second pass grades it for faithfulness against the retrieved context. If the grade is low, regenerate. Cap at one reflection round to control cost. Time: 1-2 weeks. Hallucination reduction: 20-40% on multi-hop queries.
Cost band for the full bolt-on: $8,000-$20,000 in 4-8 weeks at MarsDevs rates. Most teams ship step 1 in week 2 and have the cost savings paying for steps 2 and 3 by week 4.
No. Agentic RAG costs 3-10x more tokens and adds 2-5x latency. It is worth it for multi-hop questions, ambiguous queries, and high-stakes domains (legal, medical, financial). For FAQ bots and single-fact lookups, vanilla RAG is faster and cheaper.
At 10,000 queries per day, a vanilla RAG running around $500 per day typically becomes $1,500-$5,000 per day under agentic patterns before optimization. Caching, semantic cache, iteration caps, and Adaptive routing are the main levers. Building one at MarsDevs costs $8K-$50K total.
Vanilla RAG responds in 1-2 seconds. Agentic RAG with 3-4 iteration loops takes 8-12 seconds. If your UX needs sub-3-second response (chat, voice, search-as-you-type), use Adaptive RAG to route easy queries to the fast path and only escalate hard queries.
Yes, in three increments. Add a query classifier upfront. Add a CRAG-style retrieval evaluator. Add a self-critic on generation. Each step ships independently. Most teams take 4-8 weeks to migrate fully and see cost savings from step 1 onward.
LangGraph for stateful multi-agent control flow with persistence and human-in-the-loop. LlamaIndex Workflows for retrieval-heavy single-pipeline agentic. CrewAI for role-based prototypes. AutoGen for Azure environments. The strongest 2026 stacks combine LlamaIndex (retrieval) plus LangGraph (orchestration).
Three layers. Per-query metrics through Ragas (faithfulness ≥0.9, answer relevancy ≥0.85, context precision ≥0.8). Trajectory tracing through Arize Phoenix or Langfuse. Drift monitoring weekly on a frozen golden set. Avoid the evaluator paradox by ensembling judges and spot-checking 5% of traces.
Different jobs. GraphRAG structures knowledge as a graph and is best for cross-document reasoning and relationship queries. Agentic RAG adds an action loop and is best for multi-step reasoning and tool use. The smartest 2026 systems combine both: agentic orchestration over a graph-backed knowledge base.
Three. The 3-10x token cost versus vanilla RAG. The 2-5x latency multiplier with worse p95. The harder evaluation surface (LLM grading LLM, the evaluator paradox). Mitigations: iteration caps, Adaptive routing, frozen golden sets, ensemble evaluation, human spot-checks.
Agentic AI is the broader pattern. An LLM that plans, acts, and uses tools autonomously. Agentic RAG is the subset where the agent's primary job is retrieval: planning what to fetch, evaluating relevance, looping until grounded. All agentic RAG is agentic AI. Not all agentic AI does retrieval.
At MarsDevs, a production RAG system takes 3-16 weeks. Agentic complexity sits in the upper half: 8-16 weeks when self-correction, evaluation, observability, and migration are in scope. A simpler bolt-on (query classifier plus retrieval evaluator) ships in 4-6 weeks for $8K-$20K.
If you are scoping an upgrade from one-pass to agentic, start with the migration path in Section 12. Step 1 alone (query classification in front of your existing retriever) usually pays for itself in week three.
If you are starting from zero, the RAG fundamentals guide is the right entry point. Come back here once you have shipped a working v1 and want to upgrade.
If you are weighing approaches, read RAG vs fine-tuning and LangChain vs LlamaIndex before committing to a stack.
If you are scaling, enterprise RAG architecture patterns covers the multi-tenant, multi-region, and compliance shape of these systems.
We take on 4 new projects per month. If you are building agentic RAG and want to skip the 6-12 months of mistakes we already made, talk to our engineering team. We will tell you the honest answer on whether the upgrade earns its cost on your traffic shape, before you spend a dollar.

Co-Founder, MarsDevs
Vishvajit started MarsDevs in 2019 to help founders turn ideas into production-grade software. With deep expertise in AI, cloud architecture, and product engineering, he has led the delivery of 80+ software products for clients in 12+ countries.
Get more guides like this
Join founders, CTOs, and engineering leaders who receive our engineering insights weekly. No spam, just actionable technical content.
Partner with our team to design, build, and scale your next product.
Let’s Talk