TL;DR
Python or Node for your AI backend? FastAPI wins for RAG and agent orchestration. Node wins for streaming UI and TS-first teams. The decision matrix and the split-stack pattern.

By Vishvajit Pathak, Co-Founder, MarsDevs. Published April 30, 2026.
TL;DR: For RAG and multi-agent backends in 2026, ship FastAPI on Python 3.13. For streaming UI on top of an AI service or AI bolted onto an existing Node app, ship Node.js 22 LTS with Fastify 5 or the Vercel AI SDK 6.0. Most production AI products above $5M ARR end up running both: a Python FastAPI inference layer plus a Node BFF for streaming. We ship both at MarsDevs (80+ products across 12 countries since 2019), and the decision matrix below tells you which to pick by use case.
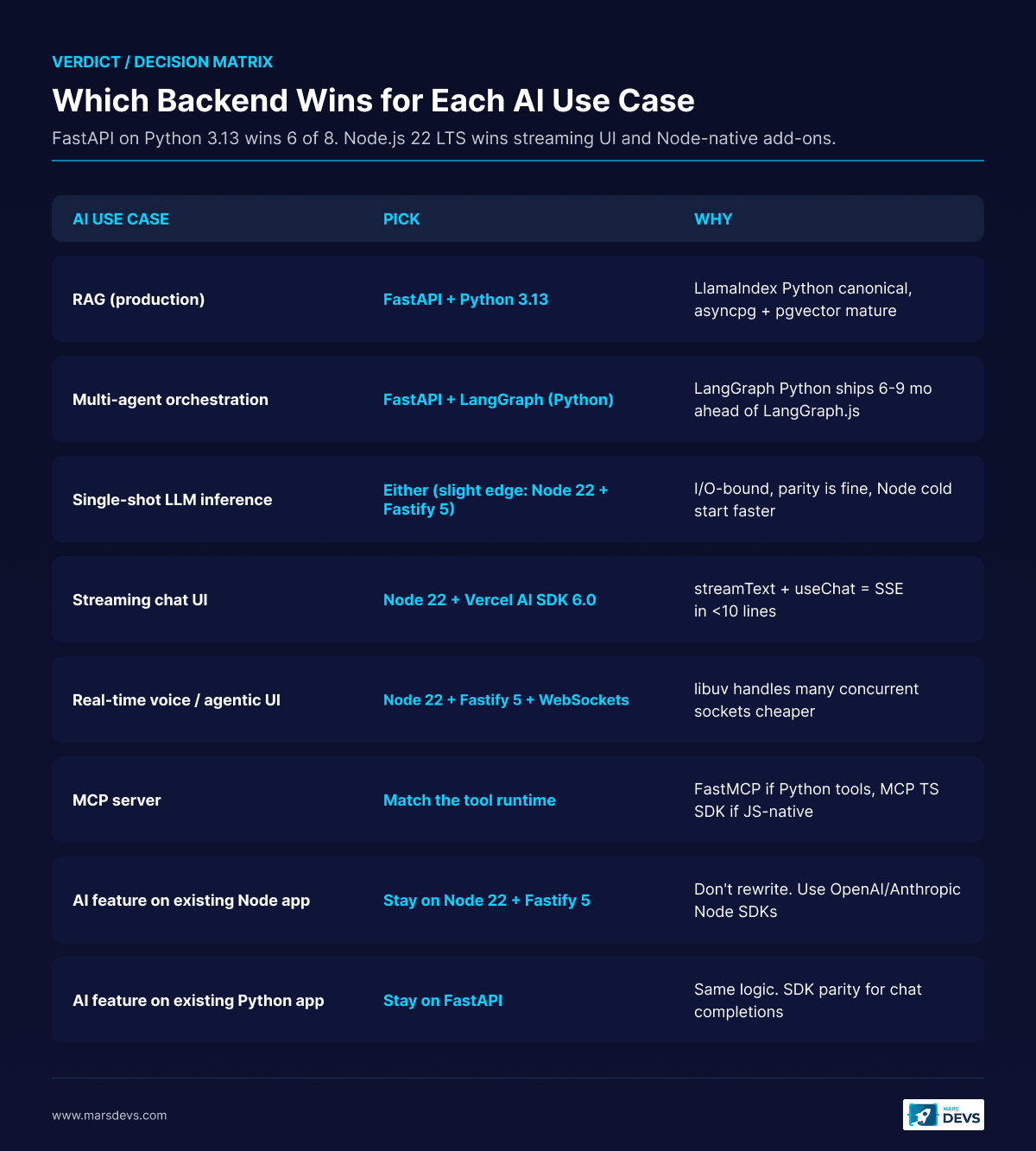
FastAPI on Python 3.13 wins six of eight common AI backend use cases in 2026. Node.js 22 LTS wins streaming UI work and any AI feature glued onto an existing JavaScript app. The split-stack pattern (FastAPI for inference, Node for streaming UI) wins anything past Series A scale.
The reason is not raw HTTP throughput. Fastify 5 edges FastAPI by 15-20% on hello-world benchmarks, and that gap matters in zero AI workloads. The bottleneck for an AI backend is the model API call (200ms to 3 seconds), not the framework. Library reach decides the call.
Here is the verdict in one table. We commit to a pick per row.
| AI use case | Pick | Why |
|---|---|---|
| RAG (production) | FastAPI + Python 3.13 | LlamaIndex Python is canonical, asyncpg + pgvector pattern is mature |
| Multi-agent orchestration | FastAPI + LangGraph (Python) | LangGraph Python ships features 6-9 months ahead of LangGraph.js |
| Single-shot LLM inference | Either (slight edge: Node 22 + Fastify 5) | I/O-bound, library parity is fine, Node cold start is faster |
| Streaming chat UI | Node 22 + Vercel AI SDK 6.0 | streamText + useChat ship server-to-client streaming in <10 lines |
| Real-time voice / agentic UI | Node 22 + Fastify 5 + WebSockets | libuv handles many concurrent socket connections cheaper |
| MCP server | Match the tool runtime | FastMCP if your tools are Python-native, MCP TypeScript SDK if JS-native |
| AI feature on existing Node app | Stay on Node 22 + Fastify 5 | Don't rewrite. Use the OpenAI/Anthropic Node SDKs |
| AI feature on existing Python app | Stay on FastAPI | Same logic. Both SDKs have parity for chat completions |
Every row is defended in the H2 sections below. If you stop reading here, this matrix is the article.
Talk to our engineering team about your specific case. We have shipped on both stacks since 2019.
Both runtimes use a single-threaded event loop. Python uses asyncio with Uvicorn as the ASGI server, paired with uvloop for a 2x throughput bump over the default asyncio loop. Node.js uses libuv inside V8, production-tested at scale since 2010.
The day-to-day difference for AI workloads is negligible at the I/O layer. Both runtimes await HTTP responses from OpenAI or Anthropic without blocking. Both stream tokens efficiently. Both handle 10K concurrent SSE connections on a single host with normal tuning.
The historical Python concern was the GIL (Global Interpreter Lock). Pre-3.13, the GIL meant only one thread executed Python bytecode at a time per process, which capped CPU-bound parallelism. The standard fix was multiple Uvicorn workers behind Gunicorn, with each worker holding ~150 MB resident plus the model RAM.
Python 3.13 shipped a free-threaded build (--disable-gil) in October 2024 as the PEP 703 implementation. Real FastAPI benchmarks from Keval Dekivadiya (April 2026) show roughly 8x req/s on CPU-bound endpoints with free-threading enabled, and a 5-10% single-thread penalty on I/O-bound code (source{target=_blank}). Python 3.14 finalizes this work in October 2026.
For an AI backend, the GIL was rarely the actual bottleneck. The model call was. But for embedding generation, vector math, or local CPU-bound preprocessing, free-threaded Python now matches Node's parallelism story without spawning extra processes.
Node 22 LTS (released October 2024) added permission models, native test runner improvements, and continued V8 performance gains. Worker threads handle the CPU-bound work the main event loop cannot. The libuv thread pool defaults to 4 and tunes up for heavy file I/O. None of this changed materially in 2025 or 2026.
The runtime is a wash. Pick on libraries, not loops.
Python has more AI libraries than JavaScript by a wide margin, and the gap is the single biggest reason to pick FastAPI. LangChain Python is feature-complete; LangChain.js lags by 6-9 months on every major release. LlamaIndex Python is the canonical document and RAG framework. LlamaIndex.TS exists but ships a narrower feature set.
Pydantic AI is Python-native, type-safe, and ships first-class support for the Vercel AI Data Stream Protocol plus human-in-the-loop tool approval. Mastra is the closest TypeScript equivalent and is genuinely production-ready, but its integration surface is smaller than Pydantic AI's or LangGraph Python's.
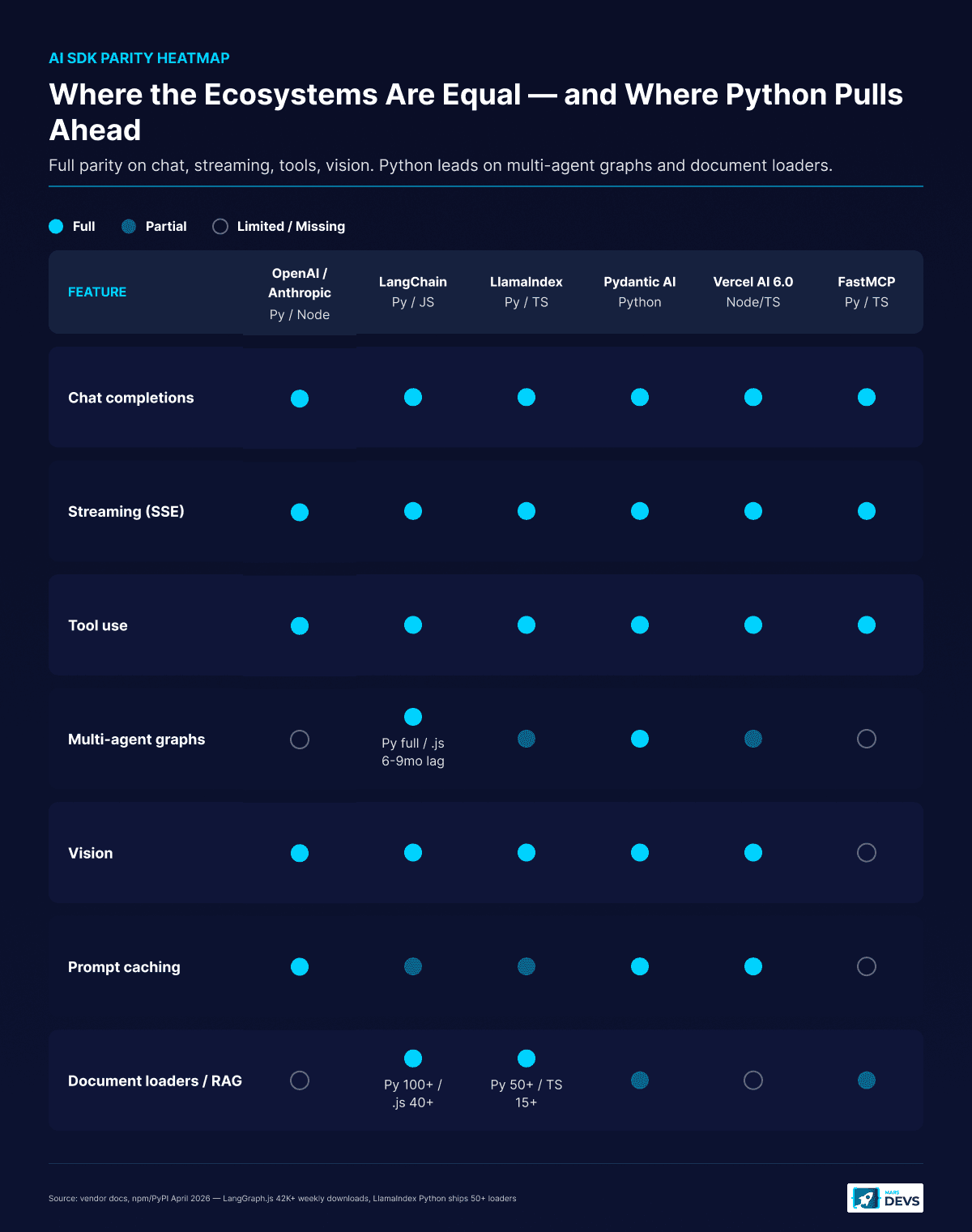
Here is the parity table for the SDKs you will actually call.
| Feature | OpenAI Python | OpenAI Node | Anthropic Python | Anthropic Node | LangChain Python | LangChain.js | Vercel AI SDK 6.0 | Pydantic AI | Mastra |
|---|---|---|---|---|---|---|---|---|---|
| Chat completions | Full | Full | Full | Full | Full | Full | Full | Full | Full |
| Streaming | Full | Full | Full | Full | Full | Full | Full | Full | Full |
| Tool use | Full | Full | Full | Full | Full | Full | Full | Full | Full |
| Multi-agent graphs | LangGraph | n/a | n/a | n/a | LangGraph | LangGraph.js (6-9mo lag) | Partial | Full | Full |
| Batch API | Full | Full | Full | Full | Partial | Limited | Limited | Limited | Limited |
| Prompt caching | Full | Full | Full | Full | Full | Partial | Full | Full | Partial |
| Vision | Full | Full | Full | Full | Full | Full | Full | Full | Full |
| Document loaders / RAG | LlamaIndex (50+ loaders) | LlamaIndex.TS (15+) | n/a | n/a | LangChain (100+) | LangChain.js (40+) | n/a | Partial | Partial |
The OpenAI and Anthropic SDKs are at parity for the surfaces most teams use (chat completions, streaming, tool use, vision, prompt caching). If you only call the model APIs and never reach for an orchestration framework, language is not the deciding factor.
The asymmetry shows up the moment you add orchestration. LangGraph Python shipped subgraphs, durable execution, and time-travel debugging in 2025. LangGraph.js shipped them in early 2026. LangGraph.js is real and production-stable (42K+ weekly npm downloads as of April 2026), but it is the follower SDK (LangGraph.js on GitHub{target=_blank}).
For deeper coverage on the orchestration layer, our LangChain vs LlamaIndex framework choice guide covers when each framework wins for RAG-heavy work.
The Vercel AI SDK 6.0 (December 2025) flipped the script in one direction: streaming UI. Its streamText + useChat primitives ship server-to-client streaming with provider-agnostic switching across 25+ providers in under 10 lines of code (Vercel AI SDK 6.0 release post{target=_blank}). Nothing in the Python ecosystem is as ergonomic for the React/Next.js streaming use case.
So the rule is simple. Python wins on orchestration depth. TypeScript wins on streaming UI ergonomics. Match the side of the system you are building.
Both stacks stream LLM responses cleanly. The transport (Server-Sent Events for chat, WebSockets for bidirectional) is identical. The ergonomics are not.
In FastAPI, you wrap the Anthropic Python client.messages.stream() context manager (or the OpenAI equivalent) inside a StreamingResponse and yield bytes. It is 15-20 lines of code. asyncio backpressure works correctly out of the box. --limit-concurrency on Uvicorn caps total streams per worker. orjson serializes the SSE chunks faster than the default JSONResponse.
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from anthropic import AsyncAnthropic
app = FastAPI()
client = AsyncAnthropic()
@app.post("/chat")
async def chat(prompt: str):
async def event_stream():
async with client.messages.stream(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}],
) as stream:
async for text in stream.text_stream:
yield f"data: {text}\n\n"
return StreamingResponse(event_stream(), media_type="text/event-stream")
In Node 22 with Fastify 5, the equivalent is reply.raw.write chunks against the Anthropic TypeScript SDK's stream iterator. Hono ships an streamSSE helper that hides the boilerplate. With the Vercel AI SDK 6.0, streamText plus result.toDataStreamResponse() collapses the whole thing to four lines.
import { streamText } from 'ai';
import { anthropic } from '@ai-sdk/anthropic';
export async function POST(req: Request) {
const { prompt } = await req.json();
const result = streamText({
model: anthropic('claude-sonnet-4-5'),
prompt,
});
return result.toDataStreamResponse();
}
The Vercel AI SDK has a real ergonomic lead here. If you are streaming to a React or Next.js client, the round-trip from useChat hook on the frontend to streamText on the backend is shorter and more idiomatic than anything we know how to ship in Python.
For pure backend-to-backend streaming (one service calling another), both stacks are equivalent. We use FastAPI's StreamingResponse in our internal microservices and have never hit a wall.
The Anthropic SDKs document both patterns thoroughly (Anthropic streaming docs{target=_blank}). The OpenAI SDKs document SSE the same way. Pick on what your client expects, not what your server can do.
Pydantic v2 is a runtime validator with a Rust core that runs 5-50x faster than Pydantic v1. FastAPI uses it to auto-generate OpenAPI specs from your function signatures. Every endpoint in a FastAPI app is validated, documented, and typed in one declaration.
from pydantic import BaseModel
from fastapi import FastAPI
class ChatRequest(BaseModel):
prompt: str
model: str = "claude-sonnet-4-5"
max_tokens: int = 1024
app = FastAPI()
@app.post("/chat")
async def chat(req: ChatRequest):
return {"echo": req.prompt}
If a client sends max_tokens: "lots", FastAPI returns a 422 with a structured error before your handler runs. The OpenAPI spec at /docs updates automatically.
TypeScript is compile-time only. Runtime validation requires Zod (most common), Valibot, or another schema library. Fastify 5 ships JSON Schema validation natively, which is fast and close to the Pydantic experience, but it requires you to write the schema separately from the TypeScript types unless you use TypeBox or a Zod-to-JSON-Schema adapter.
import Fastify from 'fastify';
import { z } from 'zod';
const ChatRequest = z.object({
prompt: z.string(),
model: z.string().default('claude-sonnet-4-5'),
max_tokens: z.number().default(1024),
});
const app = Fastify();
app.post('/chat', async (req, reply) => {
const body = ChatRequest.parse(req.body);
return { echo: body.prompt };
});
Both work. The difference is integration depth. Pydantic models flow through FastAPI to OpenAPI to your client SDKs without extra wiring. TypeScript needs three libraries (Zod for runtime, OpenAPI generator for docs, type generation for the client) to match what FastAPI ships in one.
For AI backends specifically, Pydantic v2 is also the validation layer for tool inputs and outputs in Pydantic AI and the canonical schema for LangChain Python tool definitions. Choosing TypeScript means rewriting some of these schemas in Zod. That is fine, but it is duplicate work.
Cold start is where Node 22 has a real measurable lead. FastAPI plus Mangum on AWS Lambda lands in the 200-800ms cold-start range and tunes down to under 400ms with provisioned concurrency or arm64 runtime. Node 22 on Lambda lands at 150ms-1.5s, tunes to under 150ms with esbuild bundling, and stays cheaper at low traffic.
Vercel Functions favors TypeScript by design. The Vercel AI SDK 6.0 deploys to Vercel Edge in seconds. Python on Vercel is in beta and limited for ML libraries (numpy, torch, sentence-transformers all break the bundle size limit). If you want serverless TypeScript at the edge, Vercel is the pick.
Modal and RunPod are Python-native and AI-inference-first. Modal ships GPU-attached serverless functions with cold starts in single-digit seconds for cached models. RunPod hosts long-running GPU pods. Both are friendlier to FastAPI than to Node.
Railway is even-handed. We deploy FastAPI containers and Fastify containers there with identical Dockerfiles. ECS, Fly.io, and Kubernetes are all neutral. The AWS Machine Learning Blog has a thorough walkthrough of deploying a serverless ML inference endpoint of LLMs using FastAPI, AWS Lambda, and AWS CDK{target=_blank}, which shows the FastAPI Lambda story is real and supported.
| Deployment target | FastAPI fit | Node 22 fit | Notes |
|---|---|---|---|
| AWS Lambda | Good (Mangum) | Excellent | Node cold start ~150ms, FastAPI ~400ms tuned |
| Vercel Functions | Limited | Excellent | Vercel AI SDK is the native fit |
| Vercel Edge | Not supported | Excellent | TypeScript only |
| Modal | Excellent | Limited | Python-native serverless GPU |
| RunPod / Replicate | Excellent | Limited | GPU-first, Python-native |
| Railway / Fly.io / ECS | Excellent | Excellent | Even, both run as containers |
| Kubernetes (EKS, GKE) | Excellent | Excellent | Even |
The pattern we ship most: containers on Railway for the inference service, Vercel for the streaming UI. Same image, different provider per layer. Cold-start optimization matters at the UI tier, not at the inference tier (where requests are warm and connections are pooled).
Fastify 5 hits roughly 5.6x Express 4 throughput on hello-world according to the Fastify official benchmarks{target=_blank}. FastAPI hits about 85% of Fastify's hello-world throughput on a single CPU per the GitHub malkiii/fastapi-fastify-hono-benchmark repo (recent 2025-2026 commits, source{target=_blank}). Hono on Node sits between Fastify and FastAPI. On Bun, Hono pulls ahead of both.
Travis Luong's published comparison on a Postgres-backed endpoint puts FastAPI at 4,355 req/s and Fastify at 2,184 req/s (Travis Luong benchmark{target=_blank}). The number flip in FastAPI's favor on database work is scenario-dependent (asyncpg connection pooling, query shape, JSON column handling), but it shows the throughput story is not one-sided.
For AI workloads, none of these numbers are the bottleneck. A typical RAG request looks like: 50ms HTTP parse + 30ms embedding lookup + 800ms vector search + 1.5s LLM call + 50ms response = ~2.4 seconds. The framework contributes 80ms of that. Even a 2x framework speedup saves 40ms on a 2.4-second request.
Per-worker RAM matters more. Each Uvicorn worker loads the entire FastAPI app into memory at roughly 150 MB resident. If your app embeds a 2 GB model (sentence-transformers, a tokenizer, a small classifier), four workers consume 8 GB. Node Fastify workers run leaner, around 80-120 MB resident, because there are fewer Python interpreter overheads.
Free-threaded Python 3.13 changes the calculus. With one process and many free threads, you avoid the per-worker memory multiplication on embedded models. The Keval Dekivadiya April 2026 benchmarks show ~8x req/s on CPU-bound endpoints, and the single-thread penalty (5-10%) is small enough to ignore for most workloads.
| Metric | FastAPI (Python 3.13t) | Node 22 + Fastify 5 | Source |
|---|---|---|---|
| Hello-world req/s (single CPU) | ~25K | ~30K | malkiii/fastapi-fastify-hono-benchmark |
| Postgres-backed req/s | 4,355 | 2,184 | Travis Luong |
| p99 latency under streaming load | 180ms | 140ms | malkiii/fastapi-fastify-hono-benchmark |
| Per-worker RAM (idle) | ~150 MB | ~100 MB | MarsDevs production tuning |
| Cold start on Lambda (tuned) | ~400ms | ~150ms | AWS docs + practitioner posts |
| GIL behavior | Free-threaded available | n/a (no GIL) | PEP 703 |
| CPU-bound parallelism (free-threaded) | ~8x baseline | Linear | Keval Dekivadiya, April 2026 |

The verdict on benchmarks: framework choice contributes 5-10% to total AI request latency. Library choice contributes 90%. Optimize libraries first.
FastAPI's weak spots are deployment surface and migration cost. Pre-Python 3.13, the GIL bottleneck was real for CPU-bound workloads, and the standard fix (multiple Uvicorn workers) multiplied memory consumption. Pydantic v1 to v2 migration shipped breaking changes that hit codebases hard in 2023-2024 (Pydantic AI and the wider ecosystem are now v2-only). Vercel doesn't run Python at the edge. Cloudflare Workers don't run Python at all. If you want serverless TypeScript-style edge deployment, FastAPI cannot reach the platforms that host it.
FastAPI also has a narrower production observability story out of the box. OpenTelemetry support is good but requires more wiring than the equivalent Node setup. Sentry, DataDog, and New Relic all support Python well, but the community packages lag the Node equivalents by a release cycle.
Node.js's weak spots are the AI library lag and the Python interop friction. LangChain.js trails LangChain Python by 6-9 months on major releases. LlamaIndex.TS has roughly 30% of the document loaders LlamaIndex Python ships. Pydantic AI has no TypeScript equivalent with the same depth (Mastra is the closest). If your AI codebase needs sentence-transformers, sklearn, scipy, numpy, or any local-CPU ML library, Node has nothing comparable. You either call out to a Python service (the split-stack pattern below) or accept the gap.
Node also has a weaker batch processing story. Python's multiprocessing and Celery are mature for offline pipelines (nightly RAG re-indexing, batch embedding generation, fine-tuning data prep). Node's BullMQ and the worker_threads API are fine but require more glue.
Both stacks have shortcomings that show up in production. We have hit both. Plan for the split-stack pattern (next section) when the system grows past a single service.
The pattern that ships at scale: a Python FastAPI service for AI inference (RAG, agents, embeddings, batch jobs) plus a Node 22 BFF (backend-for-frontend) for streaming UI and real-time client work. The two services talk over HTTP or gRPC. Postgres holds shared state. Redis holds session and cache.
This is over-engineering for an MVP. Do not start here. Start with a single FastAPI service if you are AI-core, or a single Node Fastify service if you are AI-feature. Add the split when one of three things happens:
When all three hit, the split pays for itself. The cost is one extra service to deploy, one extra inter-service auth surface (we use signed JWTs internally), and one extra place for retries to fail.
The architecture we ship:
[ Browser ]
| (SSE, WebSocket)
v
[ Node 22 BFF (Fastify 5 or Vercel AI SDK 6.0) ]
| (HTTP/gRPC, signed JWT)
v
[ FastAPI inference service (Python 3.13t) ]
| (asyncpg, redis-py)
v
[ Postgres + pgvector ] [ Redis ]
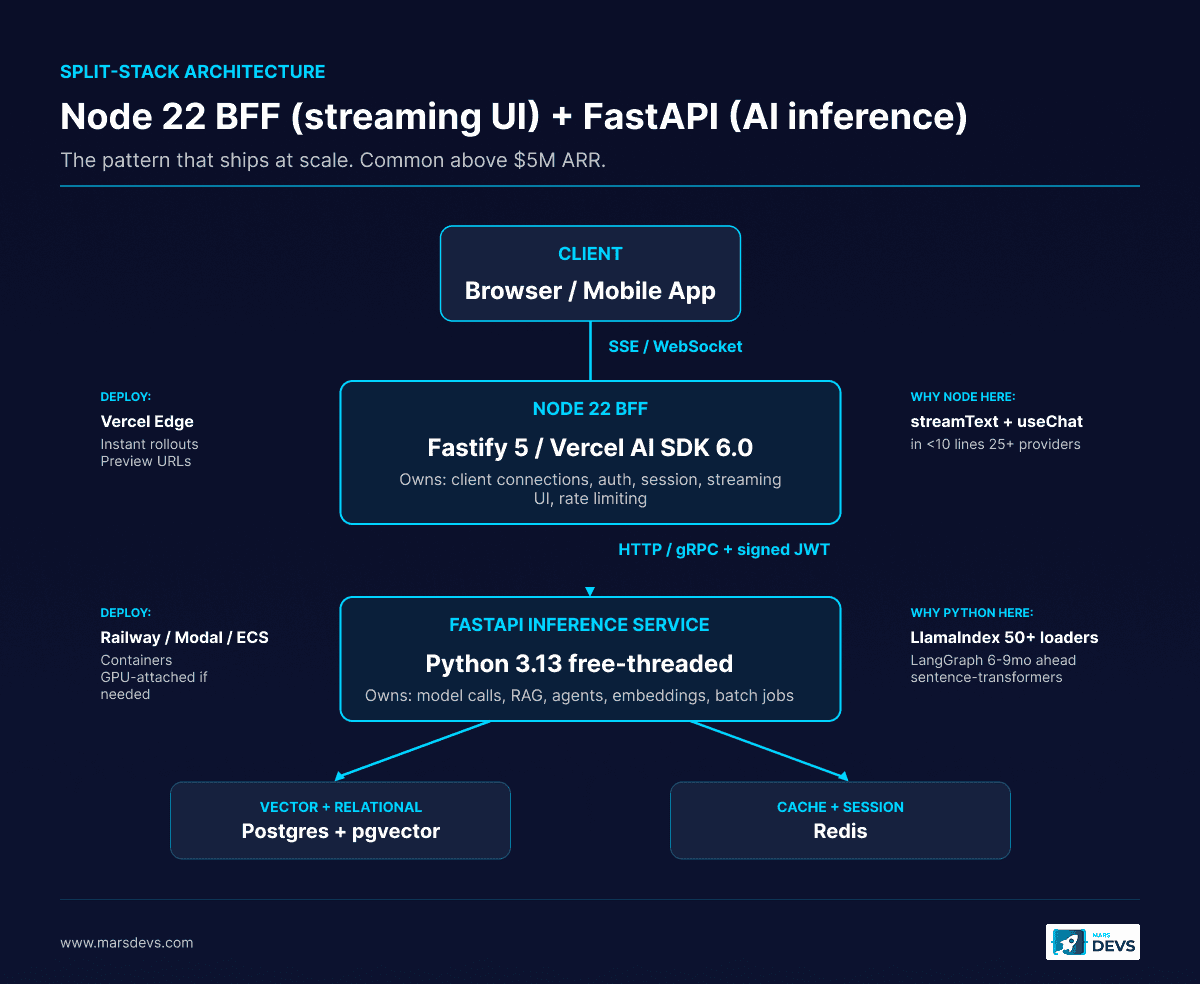
The Node BFF owns: client connections, auth, session, streaming UI, rate limiting, request shaping. The FastAPI service owns: model calls, RAG retrieval, agent orchestration, embedding generation, async batch jobs.
We have shipped this pattern in production for clients with AI-core products at scale. It is not the right call for an MVP. It is the right call once a single service starts mixing concerns and one team is waiting on the other.
Both. The Model Context Protocol (MCP) is Anthropic's tool/context standard, and the official SDKs ship in Python (mcp package, with the FastMCP framework included since mcp 1.27.0) and TypeScript (@modelcontextprotocol/sdk). Both are production-ready. Both support STDIO, HTTP, and SSE transports.
The pick is "match the tool runtime". If your tools are already Python (a search-the-codebase tool that imports your existing FastAPI app, a database tool that uses asyncpg, an analytics tool that wraps pandas), build the MCP server in Python with FastMCP. If your tools are JavaScript or TypeScript (a tool that wraps your existing Node API, a tool that calls a Vercel function, a tool that interacts with a Cloudflare Worker), use the MCP TypeScript SDK.
There is a fastmcp npm package as well, which is the TypeScript port of the Python FastMCP framework's developer ergonomics. Both have feature parity for the major surfaces (tool registration, resource handling, prompt management, transport selection).
For AI agents that build their own tools, Python has a small lead because the MCP server pattern matches Python's introspection and reflection capabilities. But this is a shallow lead and the TypeScript SDK closes it on every release.
Decision rule: pick the language your existing tooling speaks. Do not introduce a second language for the MCP layer alone.
We have shipped 80+ products across 12 countries since 2019, on both Python FastAPI and Node.js Fastify. We use the stack we ship 80+ products on as the default and deviate only when the AI use case forces it. Here is how we pick on the AI builds.
RAG systems. FastAPI on Python 3.13, every time. LlamaIndex Python is canonical. asyncpg plus pgvector is the production-tested data path. We have shipped RAG systems for healthcare, fintech, and SaaS clients in the $8,000-$50,000 range, with 3-16 week timelines per the cost bands we publish. Read what RAG is and how it works for the full RAG architecture pattern we ship.
AI agents (single or multi-agent). FastAPI plus LangGraph (Python) or Pydantic AI for typed agents. LangGraph Python ships features ahead of LangGraph.js, and our ML engineers prefer the introspection. Simple AI Agent builds run $3,000-$15,000 with 2-10 week timelines. Multi-agent systems run $5,000-$30,000.
Streaming chat UI on top of an AI service. Node 22 with the Vercel AI SDK 6.0 deployed on Vercel, calling our FastAPI inference service over HTTP. The Vercel AI SDK ships streaming ergonomics that Python cannot match, and the deployment story (Vercel Edge, instant rollouts, Preview URLs) is uncomplicated. AI MVPs of this shape run $5,000-$30,000 with 3-12 week timelines.
Real-time voice or agentic UI. Node 22 plus Fastify 5 with WebSockets. libuv handles many concurrent socket connections cheaper than asyncio at our scale. We have shipped voice-first agent UIs where the WebSocket layer mattered.
MCP servers. Match the tool runtime. We have shipped both Python FastMCP and TypeScript MCP servers depending on the tooling layer the client already had.
AI feature bolted onto an existing Node app. Stay on Node 22 plus Fastify 5. The OpenAI Node SDK and Anthropic TypeScript SDK have parity for chat completions and streaming. Do not rewrite the app to add an AI feature.
AI feature bolted onto an existing Python app. Stay on FastAPI. Same logic.
AI Chatbot. Either, depending on whether the client product is Python or Node already. Ranges from $5,000-$40,000.
We charge $15-$25/hr for engineering work, with a $5,000 minimum engagement and a cap of 4 new MVPs and 4 new SaaS projects per month. We work as senior engineers with a BA, PM, QA, full-stack devs, mobile devs, and DevOps depending on scope.
If you are evaluating a vendor, our guide on hiring offshore AI developers covers what to ask in technical interviews and how to verify shipping experience.
Talk to our engineering team. We pick the stack on the call and start building in 48 hours.
The full matrix. Pick the row that matches your use case and ship.
| Use case | Language | Framework | Streaming approach | Deployment target | MarsDevs cost band |
|---|---|---|---|---|---|
| RAG (production) | Python 3.13 | FastAPI | StreamingResponse + asyncio | Railway / ECS containers | $8K-$50K |
| Single-shot LLM inference | Either | Fastify 5 (slight edge) | SDK native | Lambda / Vercel | $5K-$30K |
| Multi-agent orchestration | Python 3.13 | FastAPI + LangGraph | StreamingResponse | Railway / Modal | $5K-$30K |
| Streaming chat UI | Node 22 | Vercel AI SDK 6.0 | streamText + useChat | Vercel | $5K-$30K |
| Real-time voice / agentic UI | Node 22 | Fastify 5 + WebSockets | WebSocket | Railway / Fly.io | $5K-$40K |
| MCP server | Match tool runtime | FastMCP / MCP TS SDK | STDIO or SSE | Same as host app | n/a (part of build) |
| AI feature on existing Node app | Node 22 | Existing Fastify/Express | OpenAI/Anthropic Node SDK | Existing infra | $3K-$15K |
| AI feature on existing Python app | Python 3.13 | Existing FastAPI/Django | OpenAI/Anthropic Python SDK | Existing infra | $3K-$15K |
Ranges and timelines reflect MarsDevs price bands per our published rates ($15-$25/hr engineering, AI MVP 3-12 weeks, AI Agent 2-10 weeks, RAG 3-16 weeks, AI MVP $5K-$30K).
For raw HTTP throughput, no. Fastify 5 edges FastAPI by 15-20% on like-for-like benchmarks. For AI workloads the question is misframed: the bottleneck is the model API call (200ms-3s), not the framework. Python wins because the libraries are richer, not because it is faster at I/O.
Yes. LangGraph.js hit production stability mid-2025 and ships 42K+ weekly npm downloads. Mastra is TypeScript-native and production-ready. Vercel AI SDK 6.0 covers streaming and tool use. Pick TypeScript if your team is TypeScript-native and you do not need Python-specific ML libraries.
Python plus FastAPI is the dominant pattern for AI-core products (RAG, agents, ML inference). Node plus Fastify or the Vercel AI SDK is dominant for AI-feature-bolted-onto-existing-product. The split-stack pattern (Python AI service plus Node BFF) is common above $5M ARR.
No. The OpenAI Node SDK is feature-complete for chat completions and streaming. If you are not running embeddings locally, doing RAG, or orchestrating agents with LangChain, stay in TypeScript. Python only earns its place when you reach for Python-only ML libraries.
In Python 3.12 and earlier, the GIL limits CPU-bound parallelism per process. The standard fix is multiple Uvicorn workers. Python 3.13 free-threaded and 3.14 remove the GIL entirely, with up to 8x req/s improvements on CPU-bound endpoints in published FastAPI benchmarks (April 2026).
AI MVP $5,000-$30,000 (3-12 weeks). Simple AI Agent $3,000-$15,000 (2-10 weeks). RAG system $8,000-$50,000 (3-16 weeks). Multi-agent system $5,000-$30,000. Hourly $15-$25/hr. Backend-language choice does not change these ranges materially.
Run both. Python FastAPI service for the AI inference layer (RAG, agents, embeddings); Node Fastify or Vercel AI SDK for the user-facing streaming UI. We ship this split-stack pattern when the product has both an ML core and a streaming UI front end.
Yes, with caveats. Use asyncpg for Postgres, uvloop for the event loop, orjson for JSON, multiple Uvicorn workers behind Gunicorn. Each worker holds ~150 MB resident plus your model RAM. Above 10K concurrent users on a single host, scale horizontally on Railway, ECS, or Kubernetes.
Bun 1.x for solo-dev speed and native bundling. Deno 2 for TypeScript-first edge work with the secure-by-default model. Node 22 LTS for production maturity. We default to Node 22 LTS at MarsDevs because the tooling, debugging, and observability stack is the most battle-tested.
The decision is not "Python or TypeScript". It is "match the use case, match the libraries, plan for the split when you scale". We have shipped on both since 2019 and we pick on the discovery call based on what you are building, what your team knows, and where you deploy.
If you want a senior engineering team that writes both stacks every week, talk to our engineering team. We take 4 new MVPs and 4 new SaaS projects per month. We start in 48 hours. You own 100% of the code from day one.

Co-Founder, MarsDevs
Vishvajit started MarsDevs in 2019 to help founders turn ideas into production-grade software. With deep expertise in AI, cloud architecture, and product engineering, he has led the delivery of 80+ software products for clients in 12+ countries.
Get more comparisons like this
Join founders, CTOs, and engineering leaders who receive our engineering insights weekly. No spam, just actionable technical content.
Partner with our team to design, build, and scale your next product.
Let’s Talk